
1. Fashion MNIST데이터 이용
저번 neural network를 학습시킬 때 이용했던 MNIST데이터를 이용하겠다.
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = \
keras.datasets.fashion_mnist.load_data()
# 채널 차원 추가
train_scaled = train_input.reshape(-1, 28, 28, 1) / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)픽셀 값의 범위를 0~ 255로 설정해주고 28*28의 열의 크기를 갖는 벡터로 변경해주었다.
그 후 scikit - learn의 메소드를 이용해 trainning data와 test data로 나눠주었다.
2. Convolution Layer만들기
model = keras.Sequential()
# First convolution layer
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu',
padding='same', input_shape=(28,28,1)))
# First pooling layer
model.add(keras.layers.MaxPooling2D(2))convolution Layer를 만들어주겠다. 일반적으로 CNN에서는 convolution 연산 -> relu(활성화 함수 적용) -> pooling( 이미지 resizing)과정을 반복하기 때문에
Keras의 Conv2D함수를 이용하면 앞선 포스팅에서 Linear 한 연산을 하던 레이어가 아닌 convolution 연산을 수행하는 layer를 만들 수 있습니다.
그 후 keras의 layer메소드에서 MAXPooling을 적용시킵니다. maxPooling은 2,2사이즈로 이미지를 나눈 뒤 그 중 가장 큰 값만 남기는 방식으로 이미지를 resizing하는 방식입니다.
# Second convolution & pooling layer
model.add(keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu',
padding='same'))
model.add(keras.layers.MaxPooling2D(2))
# Flatten
model.add(keras.layers.Flatten())
# Dense hidden layer
model.add(keras.layers.Dense(100, activation='relu'))
# Dropout layer
model.add(keras.layers.Dropout(0.4))
# Output layer
model.add(keras.layers.Dense(10, activation='softmax'))그 후 두번째 convolution 레이어를 만들어줍니다. 첫 번째 레이어와 동일하게 kernal size를 만들어주고 activation함수는 relu padding은 인풋 이미지와 아웃풋 이미지의 크기가 동일하도록 설정해줍니다.
그 후 Flatten 메소드를 적용시키는데 이 메소드는 공간 정보를 유지하고 있던 convolution레이어를 다시 1차원적으로 일렬로 나열해주는 역할을 하고 있습니다. 그 후 우리가 DNN에서 작성했던 일반적인 neural network레이어인 Dense레이어를 추가해줍니다. 이 과정에서 Drop out을 통해 과적합(overfitting)을 방지해줍니다.
model.summary()summary함수를 통해 정보를 확인하면 다음과 같습니다.
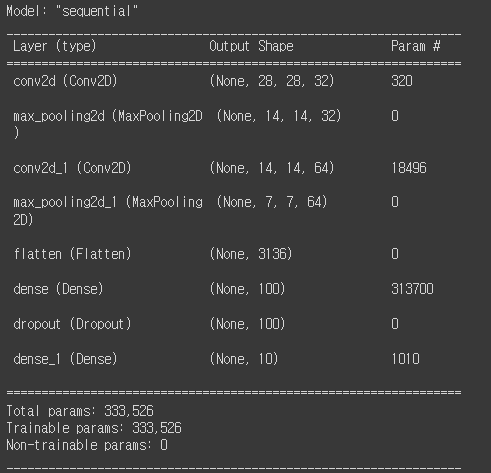
Flatten을 시켜 Fully Connected Neural Network로 만들어주면 갑자기 학습 가능한 파라미터가 확 늘어나는 것을 확인할 수 있습니다. 이 때문에 병목 현상이 일어나기도 하지만 이는 다양한 CNN Architecture에서 Global Average Pooling과 같은 trick을 이용하여 해결해가고 있습니다.
# layer의 구성을 그림으로 표현
keras.utils.plot_model(model)keras의 util의 plot을 확인해보면 그림으로 모델의 생김새를 확인할 수 있습니다.
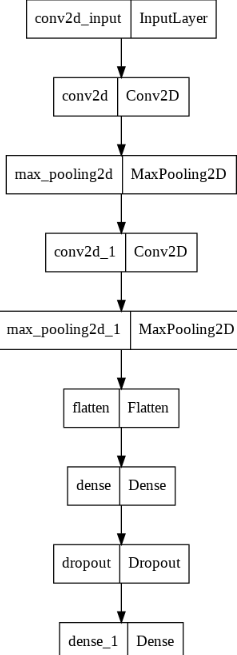
모델의 생김새를 확인해보면 다음과 같이 생겼습니다.
3. 모델 트레이닝
CNN모델을 훈련시킬 때 사용하는 다양한 메소드들이 존재합니다.
Callback - trainning 과정 중가에 어떤 작업을 수행할 수 있게 하는 객체
ModelCheckpoint Call back- 에포크마다 모델 저장
save_best_only = True = , 가장 낮은 validation loss를 만드는 모델을 저장
Early Stopping- overfitting이 시작되기 전에 training을 미리 중지하는 것
EarlyStopping callback
- patience: validation score가 향상되지 않더라도 진행할 에포크 횟수
- restore_best_weights=True: 가장 낮은 validation loss를 낸 모델 파라미터로 되돌림
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])따라서 다음과 같이 optimizer를 adam으로 설정해주고 Callback메소드를 통해 training 중간에 어떤 작업을 수행할 수 있게 해줍니다. 이 작업은 ModelCheckpoint로 에포크를 돌 때 마다 파라미터와 정확도를 확인해 save_best_only라는 옵션을 주어 가장 좋은 정확도의 모델을 저장해두는 것입니다.
early stopping 메소드를 통해 overfitting이 시작되기 전에 학습을 멈추어주었습니다.
이때 model.compile메소드는 여러가지 훈련 옵션들을 빌드하는 과정입니다. 예를 들면 optimizer는 adam loss의 종류들을 말합니다.
그리고 fit함수는 실제로 데이터를 집어 넣어 훈련을 시켜주는 메소드입니다.
4. 모델 평가
다음과 같이 matplotlib을 이용하면 training하면서 저장해 둔 loss들을 시각적으로 확인해볼 수 있습니다.
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()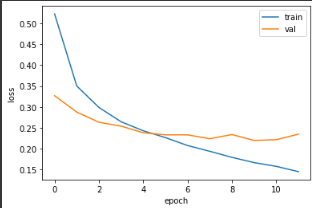
model.evaluate(val_scaled, val_target)위의 코드를 수행시켜 모델을 val데이터로 평가해보면 다음과 같습니다.

92%의 정확도를 보여줍니다.
5. Visualization of CNNS
1. Weight Visualization
CNN에서 필터를 통과 시키면 가중치가 학습이 되는데 어떤 가중치를 학습시켰는 지 확인하기 위해 사용한다.
# 체크포인트 파일 load
model = keras.models.load_model('best-cnn-model.h5')아까 callback객체를 이용해서 저장했던 모델 가중치를 불러온다.
model.layers레이어를 확인해보면 다음과 같다.
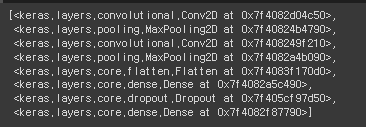
아까 설정해준 대로 Convolution 레이어 두 개와 Max Pooling을 수행하는 단계 두 개 FC Layer 3개로 구성되어 있고 Dropout을 적용시켜줬다.
conv = model.layers[0]
# weights의 첫 번째 원소 = weight, 두 번째 원소 = bias
print(conv.weights[0].shape, conv.weights[1].shape)
conv_weights = conv.weights[0].numpy()
print(conv_weights.mean(), conv_weights.std())
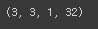
첫 번째 conv 레이어의 가중치의 모양을 확인해보면 위와 같다. 3 3 1 32의 모양을 가지고 있는데 이는 아까 커널의 사이즈가 3*3*1이 었고 필터의 개수가 32개여서 나오는 모양이다.
첫 번째 conv 레이어의 가중치들을 numpy배열화해서 평균과 표준편차를 구해보았다.

import matplotlib.pyplot as plt
plt.hist(conv_weights.reshape(-1, 1))
plt.xlabel('weight')
plt.ylabel('count')
plt.show()matplot lib을 사용해 weight들이 어떤 가중치를 가졌는지 그래프로 그려보면 다음과 같다.
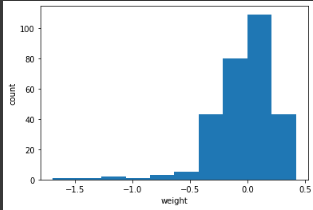
# conv_weights[:,:,0,0] ~ conv_weights[:,:,0,31]까지 출력
fig, axs = plt.subplots(2, 16, figsize=(15,2))
for i in range(2):
for j in range(16):
axs[i, j].imshow(conv_weights[:,:,0,i*16 + j], vmin=-0.5, vmax=0.5)
axs[i, j].axis('off')
plt.show()이 32개의 커널을 16개씩 2 줄로 출력해보면 다음과 같이 weight들의 가중치가 어떻게 분포하고 있는지 나오게 된다.

conv_weight배열에 있는 최대 값과 최소 값을 이용해 색을 표현하는데 가장 높은 값이면 가장 밝은 노란색으로 가장 낮으면 가장어두운 녹색으로 표현해준다.
그렇다면 이제는 학습을 진행하지 않은 conv layer의 가중치들은 어떻게 분포가 되어 있는지를 시각적으로 확인해보겠습니다.
no_training_model = keras.Sequential()
no_training_model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu',
padding='same', input_shape=(28,28,1)))no_training_conv = no_training_model.layers[0]
print(no_training_conv.weights[0].shape)
no_training_weights = no_training_conv.weights[0].numpy()
print(no_training_weights.mean(), no_training_weights.std())conv 레이어를 하나 만들어주고 print함수를 통해 shape과 layer를 확인해줍니다.
conv 레이어의 가중치map의 모양은 다음과 같이 3*3*1커널을 사용하고 32개의 필터를 사용했기 때문에 다음과 같이 나옵니다.

또한 가중치의 평균과 표준편차는 다음과 같이 랜덤하게 초기화 되어 있어 다음과 같은 값을 가집니다.
plt.hist(no_training_weights.reshape(-1, 1))
plt.xlabel('weight')
plt.ylabel('count')
plt.show()matplotlib을 사용하여 가중치들의 분포를 확인해보면 다음과 같이 나옵니다.
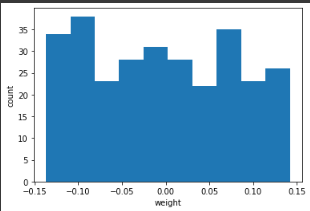
어느 한 곳에 특별히 치우치지 않고 고르게 분포를 하고 있는 것을 확인할 수 있습니다. 이는 학습되지 않고 랜덤하게 초기화가 된 상태이기 때문입니다.
fig, axs = plt.subplots(2, 16, figsize=(15,2))
for i in range(2):
for j in range(16):
axs[i, j].imshow(no_training_weights[:,:,0,i*16 + j], vmin=-0.5, vmax=0.5)
axs[i, j].axis('off')
plt.show()아까와 같은 코드로 visualization을 시켜줘도 모든 weight벡터들이 비슷하게 분포가 되어있는 것을 확인할 수 있습니다.

'파이썬 > ai' 카테고리의 다른 글
| [Ai, Python] 인천광역시 집 값 예측 프로젝트 - Feature Engineering (0) | 2022.06.25 |
|---|---|
| [ai, python] IMDB데이터베이스의 리뷰 데이터와 RNN을 이용한 리뷰 감성 분류하기 (3) | 2022.05.29 |
| [ai, python] Neural Network (1) | 2022.05.29 |
| [ai, python] 인천광역시 집 값 예측 - 모델 구축 (MLP) (0) | 2022.05.21 |
| [ai, python]인천광역시 집 값 예측 machine Learning - 데이터 전처리 3 in Colab (0) | 2022.05.21 |
댓글