
1.IMDB 리뷰 데이터 셋
IMDB에는 영화나 드라마에 대한 리뷰 데이터가 들어있는데 이 리뷰가 긍정적인 리뷰인지 부정적인 리뷰인지 분별하는 라벨또한 제공하고 있다. 만약 긍정적인 리뷰라면 1 부정적인 리뷰라면 0의 라벨을 가지고 있습니다.
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(
num_words=500)
print(train_input.shape, test_input.shape)keras에서 imdb데이터를 로드한 후 train 데이터와 test데이터의 shape을 출력해보면 다음과 같습니다.

print(len(train_input[0]))
print(len(train_input[1]))각각의 데이터의 모양을 보면 다 다른 길이를 지니고 있는 것을 확인할 수 있습니다.


print(train_input[0])다음과 같이 출력하면 아까 자주 등장하는 500개의 단어만 불러오기로 했으므로 단어별로 숫자가 mapping 된 모습이 출력되는 것을 확인할 수 있습니다. 만약 단어사전에 없는 단어들은 고유점수 2로 mapping이 되어 있습니다.

print(train_target[:20])정답지 target을 확인해보면 다음과 같습니다.

from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)
import numpy as np
lengths = np.array([len(x) for x in train_input])scikit- learn의 train_test_split함수를 이용해서 데이터를 나누고 train input을 numpy를 이용해 numpy배열로 만들어줍니다.
lengths는 이 리뷰들의 길이를 저장한 numpy배열에 해당합니다.
print(np.mean(lengths), np.median(lengths))그래서 이 길이 배열의 평균과 중앙값을 확인해보면 다음과 같습니다.
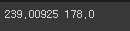
평균이 239인데 중앙값이 178인 것으로 보아 한쪽으로 치우친 형태를 띌 것을 확인할 수 있었습니다.
import matplotlib.pyplot as plt
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()matplot lib을 사용하여 데이터의 분포를 확인해보면 다음과 같습니다.
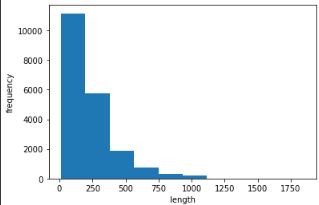
앞서 예상했던것으로 앞쪽으로 치우친 것을 확인할 수 있습니다.
2. 데이터 전처리
앞서 우리는 데이터의 분포가 앞쪽으로 치우친 것을 확인할 수 있었다. 따라서 너무 많은 데이터를 다 사용하기 보다 100보다 작은 데이터만을 사용하기로 했다.
만약 길이가 100이 되지 않는 데이터들은 padding 개념을 이용해서 0으로 채워주었다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
train_seq = pad_sequences(train_input, maxlen=100)여기서 pad_sequences라는 메소드는 keras에서 제공하는 api로 모자른 길이를 0으로 채워준다.
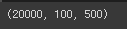
print(train_seq.shape)처리를 해준 후 결과의 shape을 확인해주면 길이를 100으로 맞춘 20000개의 데이터가 된 것을 확인할 수 있었습니다.
print(train_seq[0])첫 번째 샘플을 출력해보면
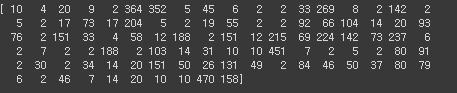
다음과 같은 형태로 데이터의 형태가 출력됩니다.
val data의 형태또한 길이를 100으로 바꿔줍니다.
val_seq = pad_sequences(val_input, maxlen=100)3. RNN모델 만들기
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 500)))
model.add(keras.layers.Dense(1, activation='sigmoid'))RNN의 모델 또한 앞서 CNN모델과 유사하지만 자기 자신으로 돌아가는 loop가 있다는 점이 차이 점입니다. 또한 순차적으로 레이어를 쌓아 학습이 되므로 keras의 Sequential메소드를 사용해서 모델을 구축할 수 있습니다.
따라서 keras의 layer의 SimpleRNN메소드를 사용해 RNN신경망을 만들어줍니다. 입력 차원은 아까 100개의 단어로 제한 했었기 때문에 100 아웃풋 차원은 500개의 단어만 사용하기로 했었기 때문에 500입니다.
그리고 FC layer를 하나 sigmoid함수를 activation 함수로 만들어줍니다. 왜냐하면 감성 분류는 binary 분류이기 때문입니다.
또한 단어를 모두 0~499로 표현하면 이러한 mapping은 랜덤인데 랜덤으로 mapping된 값이 크면 더 큰 가중치를 가지게 되는 문제점이 생기게 됩니다. 따라서 토큰에서 하나의 단어만 1 나머지는 0으로 mapping 각 단어마다 500개 0과1 크기로 맵핑이 됩니다. 그렇게 scale이 가지는 문제를 해결합니다.
train_oh = keras.utils.to_categorical(train_seq)이 API를 사용하면 one-hot encoding을 할 수 있다. 즉 500개의 단어 중 타겟 단어만 1 나머지는 0으로 변환해준다.
print(train_oh.shape)따라서 트레이닝 배열의 모양을 확인해보면
각각의 토큰마다 500개의 숫자로 one-hot encoding된 것을 확인할 수 있습니다.
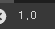
print(np.sum(train_oh[0][0]))토큰마다 encoding을 했을 때 1개가 1이고 나머지 499개의 값은 0이어야한다. 따라서 모두 더한 값은 1이 되어야한다.
따라서 sum 함수를 사용해서 토큰이 잘 encoding되었는 지 확인해보면 결과는 다음과 같다.
val_oh = keras.utils.to_categorical(val_seq)
model.summary()validation데이터 또한 one-hot encoding을 해주고 model을 summary한 정보를 확인해보면 다음과 같습니다.
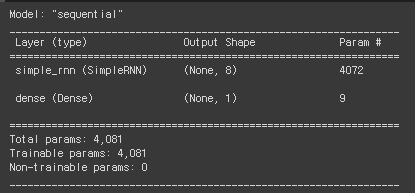
Simple RNN신경망에 4072파라미터가 들어있고 Dense레이어에는 9개의 파라미터가 들어있습니다.
이 결과를 분석해보면 우리는 아까 simpleRNN의 모델의 뉴런 개수로 8을 설정해주었습니다. 이 8개의 뉴런은 500개의 우리가 만들어준 토큰들과 fully connected되기 때문에 8*500 == 4000개의 파라미터가 존재합니다. 또한 8개이 뉴런은 각각 history로써 다른 뉴런에 다시 들어가는 과정이 존재하고 이 과정 또한 fully connected이므로 8*8인 64개가 존재하게 됩니다. 또한 뉴런마다 1개의 bias가 존재하기 때문에 8을 더해주면 4000+64+8 =4072개이 파라미터가 존재합니다.
4. RNN모델 훈련시키기
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model.fit(train_oh, train_target, epochs=100, batch_size=64,
validation_data=(val_oh, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])RNN모델에서 optimizer를 RMSprop으로 설정해주고 loss는 cross-entropy함수를 주었다. 또한 훈련하면서 callback객체를 이용하여 checkpoint를 설정해주고 early_stopping까지 설정해주어 모델의 overfitting을 방지해주고자 하였다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()matplotlib을 사용해서 loss를 그려보면 다음과 같다.
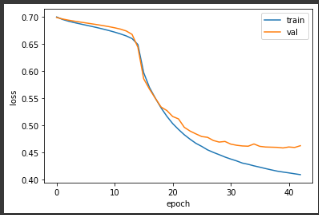
training loss는 끊임업이 잘 감소하지만 val data의 loss는 30 epoch를 넘어가자 잘 줄어들지 않는다.따라서 43번을 학습시킨 후 early stopping이 된 것을 확인할 수 있다.

5. Word Embedding- 방법 사용해서 RNN모델 만들기
아까 우리는 리뷰를 단어 별로 토큰을 만들었고 각 토큰마다 500개의 숫자로 encoding을 해주었다. 너무 비효율적인 것 같지 않은가?
그래서 나온 것이 word embedding이다. 이것은 적은 수의 byte로 각 숫자를 one-hot encoding시켜주는 것이 아니라 각각 값을 가져 단어를 구분할 수 있게 해주는 작업이다.
예를들어 원래 one-hot encoding을 통해
suri라는 단어를 00000000000000000000000001000000000000000으로encoding 했다면
word Embedding은 suri 를 0.3, 0.2, 0.6, 0.4와 같이 encoding 한다.
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500, 16, input_length=100))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
model2.summary()keras에서는 Embedding 클래스로 이러한 word embedding기능을 제공하고 있다. 이 기능을 사용해서 모델을 학습시키면 아까 one-hot encoding을 사용했을 때보다 훨씬 좋은 결과를 낸다고 합니다.
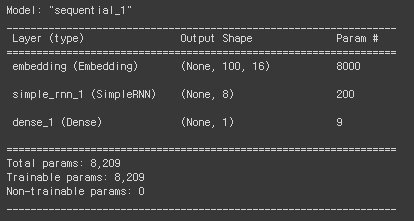
모델의 파라미터 개수를 계산해보면
embedding 클래스는 500개의 데이터를 k가 16인 벡터로 변환시키기 때문에 500 * 16 ==8000개의 파라미터를 가지게됩니다.
또한 RNN레이어에서는 뉴런의 개수가 8개라 벡터 16과 FC(Fully connected)되면 8 * 16 == 192가 되고 이 뉴런들은 다시 자기 자신을 포함한 뉴런들과 이어지므로 8*8 ==64개의 weight가 더 존재합니다.
또한 bias가 뉴런마다 존재하므로 8개를 더해주면
192 + 64+8 == 200개의 파라미터를 가지게 됩니다.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-embedding-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])모델을 훈련시키는 코드는 다음과 같이 위의 경우와 같습니다.
학습 파라미터는 아까 one-hot encoding을 사용했을 때보다 훨씬 줄어들었지만 결과는 비슷한 것을 확인할 수 있습니다.
학습을 시킨 후 정확도를 보면 78프로의 정확도를 가지는 것을 확인할 수 있었습니다.

'파이썬 > ai' 카테고리의 다른 글
| [Ai, Python] XGBOOST 회귀 모델 만들기 6 (2) | 2022.06.26 |
|---|---|
| [Ai, Python] 인천광역시 집 값 예측 프로젝트 - Feature Engineering (0) | 2022.06.25 |
| [ai, python] - Image분류 by CNN (2) | 2022.05.29 |
| [ai, python] Neural Network (1) | 2022.05.29 |
| [ai, python] 인천광역시 집 값 예측 - 모델 구축 (MLP) (0) | 2022.05.21 |
댓글