
1. 데이터 전처리
import pandas as pd # 데이터프레임 형태를 다룰 수 있는 라이브러리
import numpy as np
from sklearn.model_selection import train_test_split # 전체 데이터를 학습 데이터와 평가 데이터로 나눈다.
from sklearn.preprocessing import MinMaxScaler
# ANN
import torch
from torch import nn, optim # torch 내의 세부적인 기능을 불러온다. (신경망 기술, 손실함수, 최적화 방법 등)
from torch.utils.data import DataLoader, Dataset # 데이터를 모델에 사용할 수 있도록 정리해 주는 라이브러리
import torch.nn.functional as F # torch 내의 세부적인 기능을 불러온다. (신경망 기술 등)
# Loss
from sklearn.metrics import mean_squared_error # Regression 문제의 평가를 위해 MSE(Mean Squared Error)를 불러온다.
# Plot
import matplotlib.pyplot as plt # 시각화 도구첫 번째로 구현할 machine Learning 모델은 MLP(multiple Layer Perceptron) 이었다. 입력층과 출력층이 존재하고 그 사이에 은닉층 2개를 추가하여 MLP모델을 구현할 것이다.
그 전에 우리는 데이터를 모델에 넣기 위해서 데이터를 전처리 해주어야하는데 이 때 사용하는 대표적인 라이브러리들이 pandas와 numpy 그리고 sklearn 이다. 데이터를 전처리 해주기 위해서 나는 다음과 같은 라이브러리들을 추가해주었다.
2. 데이터 불러오기
file_name = 'AllData.xlsx'
df = pd.read_excel(file_name)
display(df)pandas라이브러리의 read_excel 함수를 통해 앞선 포스팅에서 모았던 데이터들을 저장한 엑셀 파일을 불러주었다.
그리고 그 데이터들을 출력해주면 다음과 같다.
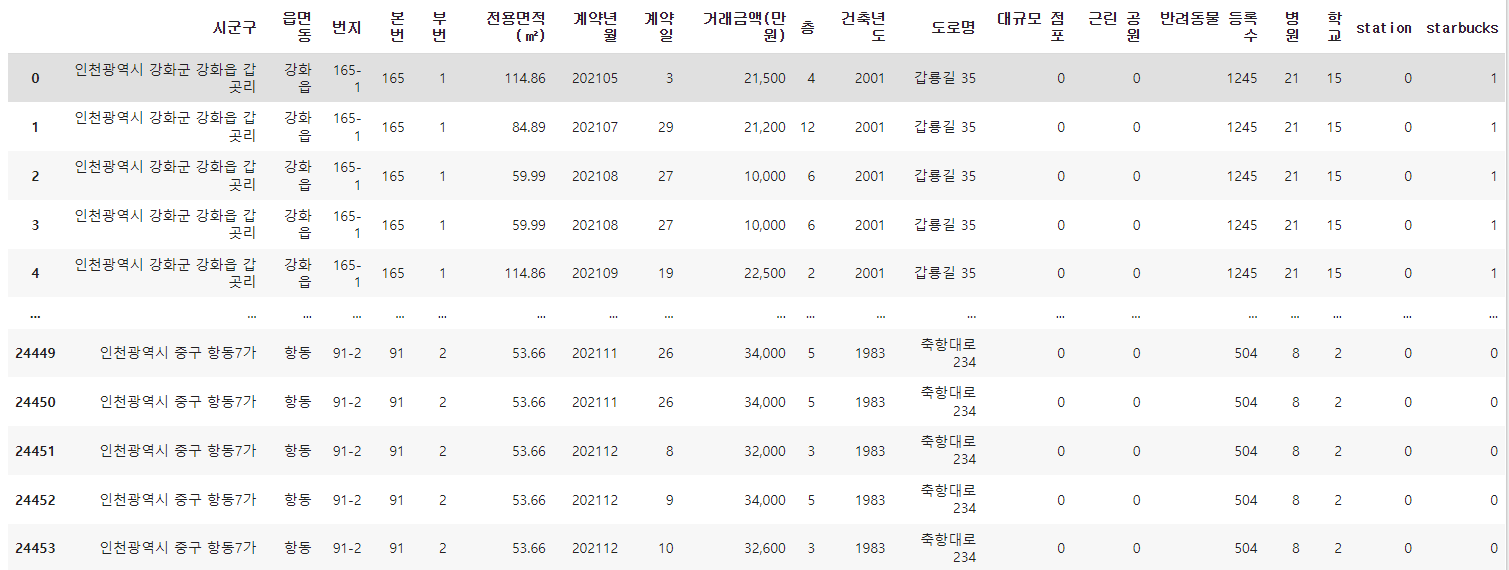
df.columns # 변수 명 확인
print(df['거래금액(만원)']) # 우리가 타겟 값으로 지정할 거래금액 (정답 지)
df.head()
df.info()
df.head() 데이터 프레임의 head함수는 앞에 5열에 해당하는 데이터들을 보여준다. 그리고 데이터 프레임에서 info함수는 그 데이터 프레임의 속하는 데이터 속성들과 그 속성들의 개수 그리고 그 데이터의 자료형을 포함한 정보를 출력해준다. 결과는 위와 같다.
3. 데이터 스케일링(MinMaxScaler)
df_copy = df.copy();
drop_list = ['번지','본번','부번','계약일', '읍면동','도로명']
for i in drop_list:
df_copy = df_copy.drop(i, axis= 1) # 필요 없는 특성은 df에서 제거해준다.
df_copy['거래금액(만원)'] = df_copy['거래금액(만원)'].str.replace(',','')
df_copy.rename(columns={'전용면적(㎡)':'전용면적', '거래금액(만원)': '거래금액'}, inplace=True) # 이름 재정의
df_copy['시군구'] = df_copy['시군구'].astype('category').cat.rename_categories({string : i for i,string in enumerate(df_copy['시군구'].unique())})
df_copy['전용면적'] = df_copy['전용면적'].astype('float32')
df_copy['계약년월'] = df_copy['계약년월'].astype('float32')
df_copy['거래금액'] = df_copy['거래금액'].astype('float32')
df_copy['층'] = df_copy['층'].astype('float32')
df_copy['건축년도'] = df_copy['건축년도'].astype('float32')
df_copy['대규모 점포'] = df_copy['대규모 점포'].astype('float32')
df_copy['근린 공원'] = df_copy['근린 공원'].astype('float32')
df_copy['반려동물 등록수'] = df_copy['반려동물 등록수'].astype('float32')
df_copy['병원'] = df_copy['병원'].astype('float32')
df_copy['학교'] = df_copy['학교'].astype('float32')
df_copy['station'] = df_copy['station'].astype('float32')
df_copy['starbucks'] = df_copy['starbucks'].astype('float32')
df_copy.head()
df_copy.info()우선 .copy()함수를 이용해 데이터 프레임의 복사본을 만들어주고 데이터에서 신경망을 학습시킬 때 필요없는 속성인 '번지', '본번', '부번', '계약일', '읍면동', '도로명' 을 droplist 로 만들어주어 for문을 돌면서 .drop함수로 제거해준다.
그 후 학습에 필요한 데이터들이 원래 int64자료형의 데이터로 되어있었으므로 float형으로 변경해주기 위해 .astype함수를 이용해 float32타입으로 변경해준다.
그 후 info함수를 이용해 출력하면 다음과 같이 나온다.

모두 24454개의 데이터가 들어간 것을 확인할 수 있었고 float32형으로 변경이 된 것을 확인할 수 있었다.
그러나 한 가지 문제가 더 존재했다. 바로 각 데이터의 범주별로 데이터의 스케일이 다른 것이다.
예를 들면 반려동물 등록 수는 각 동별로 5000개에서 0개까지 존재하는데 스타벅스 개수 같은 경우는 많아봤자 5개라 반려동물 등록 수가 결과에 훨씬 더 큰 영향을 미칠 수 있는 것이다. 따라서 데이터 Scaling을 통해 데이터들을 균일하게 만들어 줘야한다.
방법은 데이터 범주 별로 존재하는 최대값 - 최소값으로 각각의 데이터에서 최소값을 뺀 값을 나눠주는 것이다. 이렇게 해주면 모든 데이터들이 0 ~ 1의 범위를 가지게 된다. 하지만 이를 코드로 돌릴 수도 있고 이러한 기능을 제공해주는 라이브러리를 이용해도 된다. 나는 sklearn에서 제공하는 MinMaxScaler를 이용했다.
df_copy_make = df_copy.filter(['전용면적', '계약년월', '거래금액', '층','건축년도','대규모 점포','근린 공원','반려동물 등록수', '병원','학교','station','starbucks'])
df_copy_make.info()
X = df_copy_make.drop('거래금액', axis=1).to_numpy() #데이터 프레임에서 타겟값(거래금액(만원))을 제외하고 넘파이 배열로 만들어준다.
Y = df_copy_make['거래금액'].to_numpy().reshape((-1,1)) # 데이터 프레임 형태의 타겟 값을 넘파이 배열로 만들어준다.
#데이터 스케일링
#sklearn에서 제공하는 MinMaxScaler
#(X- min(X)) / (max(X)-min(X))을 계산
scaler = MinMaxScaler()
scaler.fit(X)
X = scaler.transform(X)
scaler.fit(Y)
Y = scaler.transform(Y)학습에 이용할 모든 데이터들을 집어 넣고 정답에 해당하는 거래금액을 제외한 train data set을 만들어준다. 또한 정답 값만 존재하는 label도 numpy배열로 만들어준다. 그 후 MinMaxScaler를 통해 train data들만 0~1의 범위로 바꿔준다.
이 때 scaler.fit함수와 sclaer.transform함수를 이용한다.
결과는 다음과 같다.

앞선 info에서 거래금액이 빠져 총 11개의 변수가 존재하는 것을 확인할 수있다.
4. 텐서 데이터와 배치 만들기
이제 이렇게 scaling한 데이터들을 텐서 데이터로 변경해주고 한 번에 학습을 시키는 양인 배치를 만들어주어야한다.
#데이터를 텐셔 형태로 변환해주는 클래스
class TensorData(Dataset):
def __init__(self, x_data, y_data):
self.x_data = torch.FloatTensor(x_data)# Double Tensor는 Float64로 변환 Float Tensor는 Float32로 변환
self.y_data = torch.FloatTensor(y_data)
self.len = self.y_data.shape[0]
def __getitem__(self, index) :
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len다음 클래스는 데이터 셋을 Tensor data로 변경해주는 클래스이다. 이 클래스의 init함수에 데이터를 넣어주면 파이토치의 FloatTensor함수를 이용해서 데이터들을 텐서 데이터로 변경해준다.
그리고 라벨의 데이터 또한 FloatTensor함수를 이용해 텐서 데이터로 변경해준다.
#scikit-learn 을 이용해서 학습 데이터와 평가 데이터로 나눈다.
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size= 0.5) # hyper parameter 테스트 사이즈
# train데이터와 validation 데이터로 나눈다.
X2_train, X_val, Y2_train, Y_val = train_test_split(X_train, Y_train)
#학습 데이터랑 시험데이터를 배치 형태로 구축한다.
print(X2_train.shape)
print(X2_train.ndim)
print(X_val.shape)
print(Y2_train.shape)
print(Y2_train.ndim)
print(Y_val.shape)
trainsets = TensorData(X2_train, Y2_train)
trainLoader = torch.utils.data.DataLoader(trainsets, batch_size = 32, shuffle=True) # 하이퍼 파라미터 배치 사이즈
validationsets = TensorData(X_val, Y_val) #validation set
validationLoader = torch.utils.data.DataLoader(validationsets, batch_size=32, shuffle=True)
testsets = TensorData(X_test, Y_test) # 테스트 데이터들을 나눠준다.
testloader = torch.utils.data.DataLoader(testsets, batch_size = 32, shuffle=True)이제 학습 데이터와 평가 데이터로 나눠보겠다. 왜냐하면 모델을 학습시킬 데이터와 Test를 할 데이터를 따로 구분해주어야하고 중간에 모의고사 같은 느낌의 데이터인 validation 데이터 또한 나눠주어야한다. 우리가 모은 24454개의 모든 데이터를 학습하는데 사용하는 것은 아니다.
나는 sklearn.train_test_split함수를 이용해 나눠주었고 이 함수를 두 번 이용해 첫 번째는 전체 데이터 셋을 shuffle한 후 train data와 test data로 나눠주었고 train data를 다시 train_test_split함수를 이용해 다시 둘로 나눠 train data와 validation data로 나눠주었다.
그 후 파이토치의 torch.utils.data.DataLoader를 이용해서 배치를 만들어주었는데 한 번에 학습시키는 데이터의 양인 batch를 32로 설정해주었다. 그 후 트레인 데이터와 validation 데이터의 모양을 출력해보면 다음과 같다.
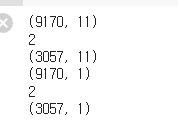
train data는 변수 11개의 9170개의 데이터이고 validation data는 3057개의 데이터이다.
'파이썬 > ai' 카테고리의 다른 글
| [ai, python] Neural Network (1) | 2022.05.29 |
|---|---|
| [ai, python] 인천광역시 집 값 예측 - 모델 구축 (MLP) (0) | 2022.05.21 |
| [ai, python] 인천광역시 집값 예측 프로젝트- 데이터 전처리 2 (0) | 2022.05.18 |
| [ai, Python] 인천시 집 값 예측 프로그램-1(데이터 수집 및 전처리1) (2) | 2022.05.17 |
| [Ai, Python] 다중 분류 KNN을 이용한 multi class classification (4) | 2022.04.11 |
댓글