
Feature Engineering
1. 변수 선정
집 값이라는 것은 매우 많은 요소들이 복합적으로 뒤 섞여 정해지는 수치이다.
하지만 우리가 고려할 수 있는 변수의 수는 물리적으로 제한되어져 있다.
나는 집 값을 결정하는 수 많은 요소 중 그나마 연관이 깊을 것이라고 생각되는 변수 11개를 뽑아 학습 데이터를 만드려고 한다.
우리 팀이 선정한 11개의 변수는 다음과 같다.
- 전용면적
- 계약녀월
- 층
- 건축년도
- 대규모 점포
- 근린 공원
- 반려동물 등록 수
- 병원
- 학교
- 주변 지하철 역 개수
- 스타벅스 수
2. 데이터 형태 변환
나는 xlsx 파일에 데이터를 모았으므로 pandas의 read_excel함수가 필요했다. 따라서 작성한 코드는 다음과 같다.
file_name = 'AllData.xlsx'
df = pd.read_excel(file_name)
display(df)위의 코드를 통해 데이터 프레임을 보여주자 다음과 같은 화면이 보였다.
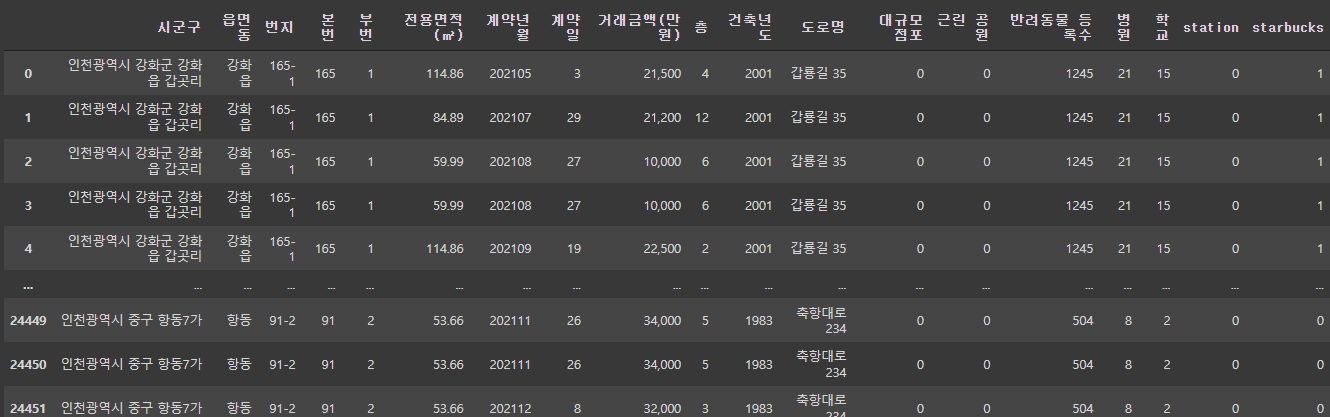
df.info()함수를 사용하면 데이터 프레임이 어떠한 column을 가지고 있고 데이터의 형태는 무었인지 알 수 있다.
print(df['거래금액(만원)']) # 우리가 타겟 값으로 지정할 거래금액 (정답지)
df.info()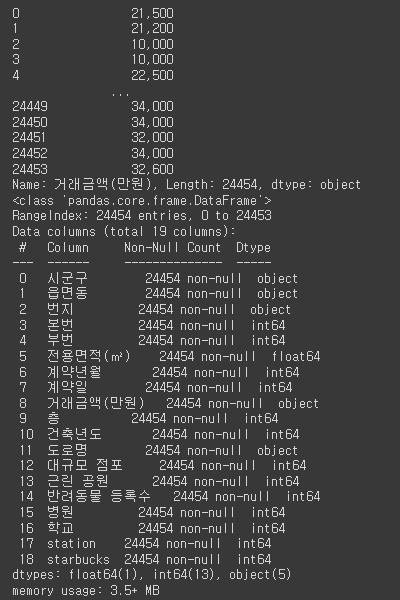
나는 날짜 형식이 모두 올바르게 작성되어 있는지 확인하기 위해 regex(정규표현식)을 이용했다.
import re
def regex(data):
pattern = re.compile('^[0-9]{6}')
match = pattern.match(data)
if match:
return True
else:
return False
date_pattern_check_series = df['계약년월'].apply(lambda data: regex(str(data)))
print(all(date_pattern_check_series))
del date_pattern_check_series
결과는 True였기 때문에 그대로 진행했다.
우선 category데이터와 수치 데이터를 나눠줄 필요성이 있었다. 여기서 category데이터란 아파트나 주택이 속한 위치적 정보 즉 읍/면/동 중 동을 선택했다.
그 후 데이터 프레임에서 필요없는 요소인 번지, 본번, 부번, 계약일, 도로명과 같은 요소들은 drop해주었다.
df_copy = df.copy();
drop_list = ['번지','본번','부번','계약일','도로명']
for i in drop_list:
df_copy = df_copy.drop(i, axis= 1) # 필요 없는 특성은 df에서 제거해준다.그 후 데이터의 처리를 용이하기 위해 모든 수치 데이터들을 float32 자료형으로 변환해주었다.
df_copy['거래금액(만원)'] = df_copy['거래금액(만원)'].str.replace(',','')
df_copy.rename(columns={'전용면적(㎡)':'전용면적', '거래금액(만원)': '거래금액'}, inplace=True) # 이름 재정의
df_copy['시군구'] = df_copy['시군구'].astype('category').cat.rename_categories({string : i for i,string in enumerate(df_copy['시군구'].unique())})
df_copy['읍면동'] = df_copy['읍면동'].astype('category').cat.rename_categories({string : i for i,string in enumerate(df_copy['읍면동'].unique())})
df_copy['전용면적'] = df_copy['전용면적'].astype('float32')
df_copy['계약년월'] = df_copy['계약년월'].astype('float32')
df_copy['거래금액'] = df_copy['거래금액'].astype('float32')
df_copy['층'] = df_copy['층'].astype('float32')
df_copy['건축년도'] = df_copy['건축년도'].astype('float32')
df_copy['대규모 점포'] = df_copy['대규모 점포'].astype('float32')
df_copy['근린 공원'] = df_copy['근린 공원'].astype('float32')
df_copy['반려동물 등록수'] = df_copy['반려동물 등록수'].astype('float32')
df_copy['병원'] = df_copy['병원'].astype('float32')
df_copy['학교'] = df_copy['학교'].astype('float32')
df_copy['station'] = df_copy['station'].astype('float32')
df_copy['starbucks'] = df_copy['starbucks'].astype('float32')그 후 데이터 프레임을 확인해보면 다음과 같다.
df_copy.head()
df_copy.info()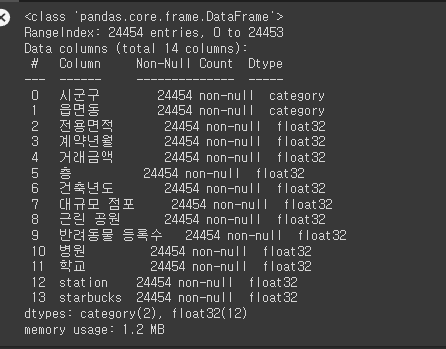
다음과 같이 쓸모 없는 정보들은 drop되고 필요한 정보들이 학습에 용이한 데이터 자료형으로 변환되어 데이터 프레임에 저장된 것을 볼 수 있다.
3. 변수 특성 추출 - 특수한 변수 완화
나는 우선 집 값이 정책이라는 특수한 변수에 의해 좌지우지 되는 폭이 크다는 점에 주목했다. 따라서 시기 별로 주택의 거래량과 그 거래량의 평균 가격들을 그래프로 그려보았다.
df_copy['계약년월'] = df_copy['계약년월'].astype('object')
df_copy['yrmth'] = df_copy['계약년월']
df_copy.to_excel("./Data.xlsx")
yrmth_df = df_copy.groupby('yrmth')['거래금액'].agg(AVG = 'mean', total ='count')
#yrmth_df = df_copy.groupby('yrmth')['거래금액'].agg(total = 'count')
yrmth_df.info()
vmin = np.min(yrmth_df['total'])
vmax = np.max(yrmth_df['total'])
plt.figure(figsize=(20, 10))
plt.scatter(np.arange(yrmth_df.shape[0]), yrmth_df['AVG'], c=yrmth_df['total'],
s=yrmth_df['total'], vmin=vmin, vmax=vmax, cmap=plt.cm.Reds)
plt.colorbar(label='total')
plt.plot(np.arange(yrmth_df.shape[0]), yrmth_df['AVG'])
plt.title('Monthly Average Price')
plt.xticks(np.arange(yrmth_df.shape[0]), yrmth_df.index.values)
plt.xlabel('YYYYMM - YearMonth')
plt.ylabel('log_Price')
plt.show()matplotlib 라이브러리를 사용하여 그래프를 그렸고 컬럼명이 한글이면 matplotlib이 인식하지 못하는 문제가 생겨서 계약년월을 yrmth로 변환해준 후 그래프 그리기를 진행했다.
다음 그래프는 높을 수록 평균 거래금액이 높고 해당하는 원의 색이 진할 수록 거래량이 많다는 뜻이다.
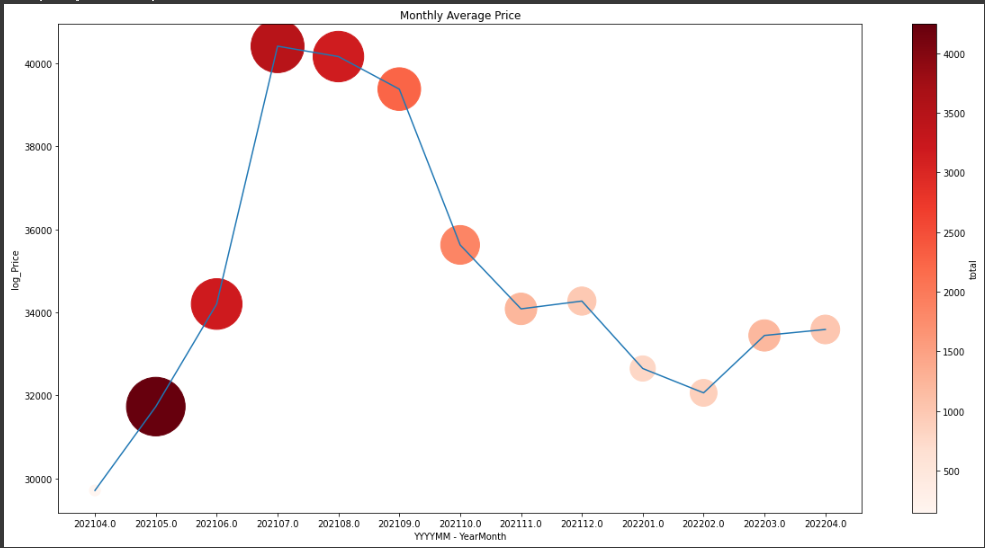
내가 모은 데이터는 2021-04 부터 2022 -04까지의 1년간 모든 인천광역시 내의 주택 거래기록이었다. 그래프를 그려 나타내보니 특이하게 2021-07월과 2021-08월의 데이터가 유난히 높다는 사실을 알게 되었다. 이것은 주변 시설이나 면적 층수 와는 관련없는 변수가 개입했다는 판단에 해당 데이터들은 제외한채 2021-03 2021-02월의 데이터를 추가해 학습을 진행하고자 했다.
4. 변수별 경향성 파악
나는 선정한 변수들의 변화에 따라 정말 집 값이 경향성을 보이는 지 확인해보기 위해 수집한 모든 데이터데 대하여 matplotlib을 이용하여 변수들이 정말 집 값의 경향성에 영향을 미치는 지 파악해보기로 했다.
others = ['전용면적', '층', '건축년도', '대규모 점포', '반려동물 등록수', '근린 공원']
plt.figure(figsize=(20, 15))
for index, item in enumerate(others):
plt.subplot(321+index)
sns.boxplot(x=item, y='거래금액', data=df_copy)다음은 모든 데이터에 대해서 집 값에 따른 변수들의 분포를 확인해보기로 했다.
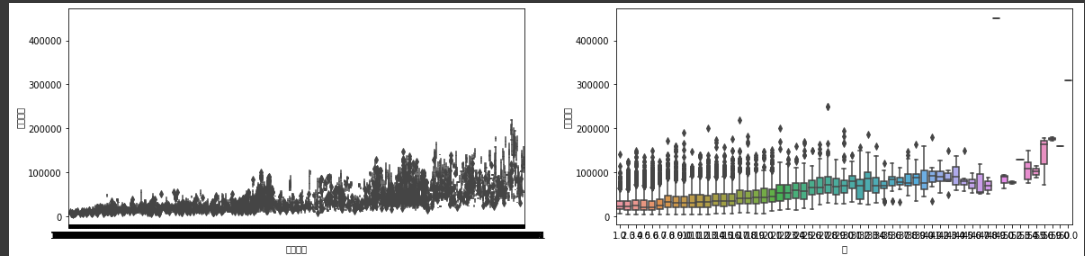
우선 전용면적과 층에 대한 그래프이다.
세로축은 모두 거래금액 가로축은 변수의 값이다. 두 그래프를 보면 알 수 있듯이 전용면적이 커지고 층이 높아지면 거래금액이 올라가는 경향성을 보이는 것으로 판단하여 변수에 선정하였다.
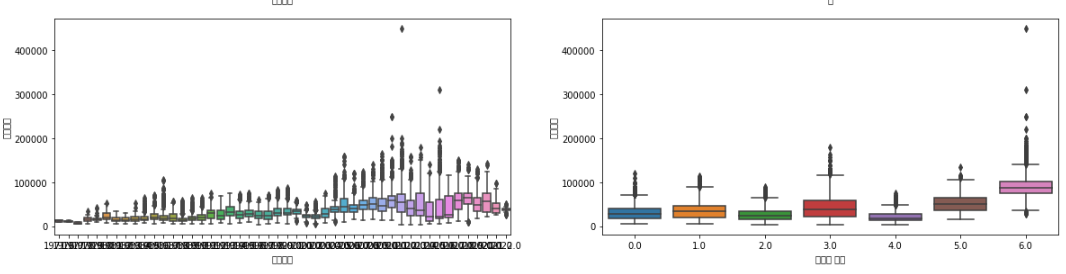
다음은 건축년도와 대규모 점포 수에 대한 그래프이다. 확실히 건축년도는 최근일 수록 대규모 점포는 많을 수록 주변 거래금액이 높은 경향성을 보이고 있다. 따라서 변수로 선정했다.
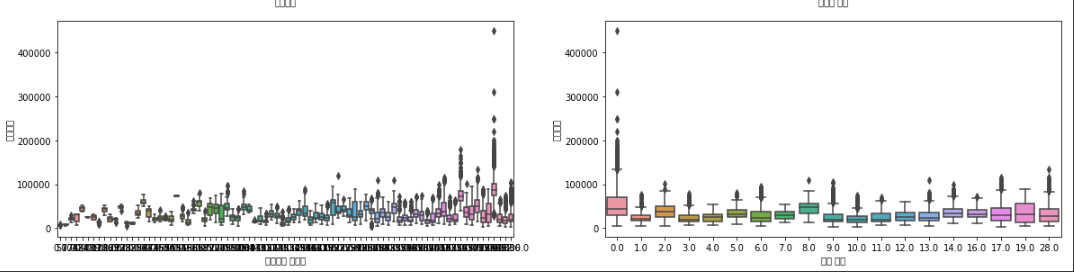
다음은 반려동물 등록 수와 근린공원이다. 마찬가지로 경향성을 보인다. 한가지 특이점은 근린 공원의 경우 역 경향성을 보이는 것이었다. 공원이 없을 수록 주변 거래금액이 높은 특성을 보였는데 이는 집 값이 높은 동네일 수록 부지가 사무실이나 편의시설 등 다른 용도로 사용되는 경우가 많고 위의 근린 공원의 수 데이터는 공원의 질은 고려하지 않은 채 공원의 양만을 고려한 데이터이기 때문으로 생각 되었다.
others2 = ['병원', '학교', 'station', 'starbucks']
plt.figure(figsize=(20, 15))
for index, item in enumerate(others2):
plt.subplot(321+index)
sns.boxplot(x=item, y='거래금액', data=df_copy)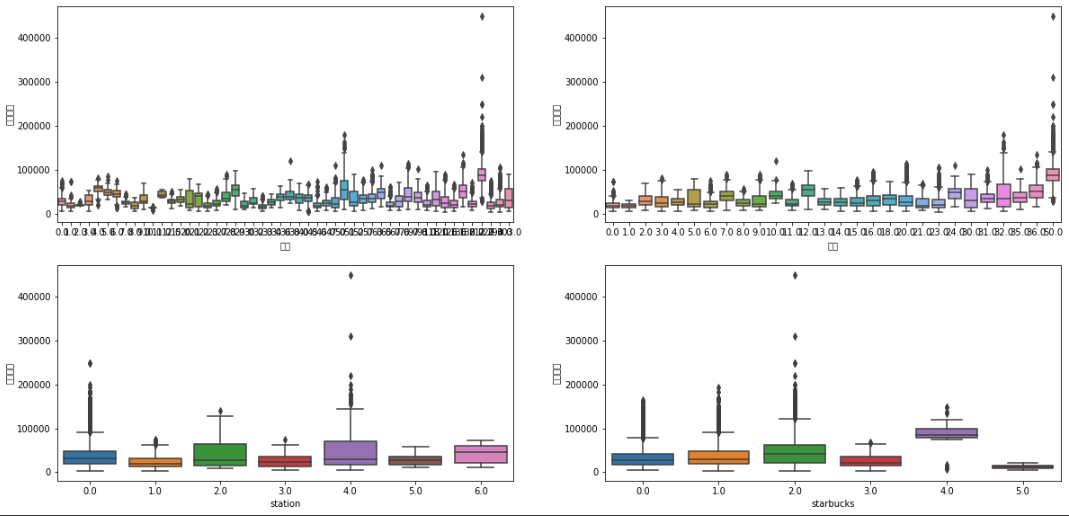
병원 학교 주변 지하철역 개수 스타벅스에 대한 경향성도 확인해봤는데 지하철 역 개수는 그나마 경향성을 보이는 반면 스타벅스 개수는 뚜렷한 변수는 보이지 않았지만 overfitting 방지를 위해 변수로 선정했다.
5. 변수 간의 상관계수 파악 (correlation)
상관계수를 분석하기 위해 seaborn 라이브러리를 이용했다.
# Plot
import matplotlib.pyplot as plt # 시각화 도구
import seaborn as sns
#상관계수 분석
plt.figure(figsize=(12,6))
sns.heatmap(df_copy_english.select_dtypes(np.number).corr(),annot=True)
plt.show()다음과 같이 seaborn라이브러리를 이용하여 변수 간의 상관계수를 분석한 heatmap을 그리면 다음과 같다.
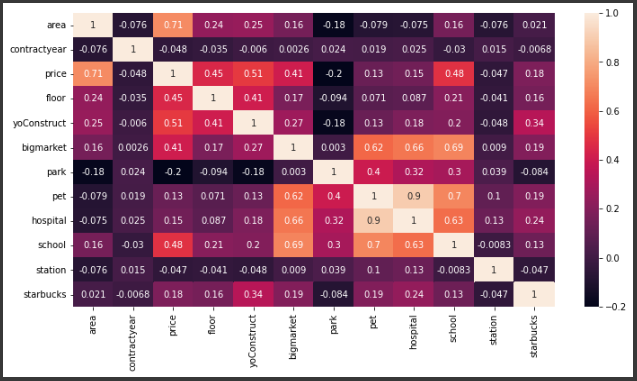
나는 서로 상관계수가 큰 변수가 있다면 원래 제거하고 학습을 진행하려 했으나 이 또한 하이퍼 파라미터에 해당하기 때문에 팀원 간의 논의를 거쳤다. 결론은 변수의 수가 11개로 부족하니 3개의 변수 이상 상관계수가 높게 나오면 하나를 제거하려 했으나 병원과 반려동물 등록수의 상관계수만 0.9로 특징있게 높을 뿐 다른 변수와의 상관계수는 크게 고려할 사항이 아니라고 판단하여 그냥 11개의 변수 모두를 학습 데이터 변수에 선정하였다.
또한 seaborn도 matplotlib과 마찬가지로 column명이 한글이라면 출력이 안되는 문제가 있어 데이터 프레임을 복사한 후 그 데이터 프레임의 column명을 모두 영어로 변경해준 후 heatmap을 출력해주었다.
6. 결론
따라서 최종적으로 선정된 변수는 다음과 같다.
- 전용면적
- 계약년월
- 층
- 건축년도
- 대규모 점포 수
- 근린 공원
- 반려동물 등록 수
- 병원
- 학교
- 주변 지하철 역 개수
- 주변 스타벅스 수
'파이썬 > ai' 카테고리의 다른 글
| [Ai, Python] Streamlit을 이용한 모델 시각화-7 (인천광역시 집 값 예측) (2) | 2022.06.26 |
|---|---|
| [Ai, Python] XGBOOST 회귀 모델 만들기 6 (2) | 2022.06.26 |
| [ai, python] IMDB데이터베이스의 리뷰 데이터와 RNN을 이용한 리뷰 감성 분류하기 (3) | 2022.05.29 |
| [ai, python] - Image분류 by CNN (2) | 2022.05.29 |
| [ai, python] Neural Network (1) | 2022.05.29 |
댓글