
1. multi-class-classification
앞선 포스팅에서 분류 모델의 경우 모두 2개의 집합 중 하나의 집합으로 새로운 데이터를 예측하는 작업을 했다면 이번에는 KNN을 사용하여 여러 개의 집합 중 하나로 예측하는 작업을 해볼 것이다.
예를 들면 이 동물이 개냐 고양이냐 만을 분류하는 것이 아니라 이 동물이 개냐 고양이냐 개구리냐 너구리냐 등과 같이 다양한 집합이 존재하는 것이다.
2. multi-class-classification의 구현
1. 데이터 전처리
다중 분류를 수행하기 위해서 python의 데이터 분석 라이브러리의 바이블 pandas라이브러리를 사용하겠다.
pip install pandasimport pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
fish.head()
#판다스 라이브러리를 통새 csv파일을 읽고 데이터 프레임으로 변환하는 과정
print(pd.unique(fish['Species']))
#unique api는 각 항목에 대해 겹치지 않는 고유한 값들을 반환한다.pandas의 read_csv함수를 통해 csv파일을 읽어온 후 판다스에서 제공하는 데이터 구조인 데이터 프레임으로 변경하는 과정이다.
데이터 프레임이란 흔히 볼 수 있는 표나 엑셀 시트와 같은 데이터 형태를 말한다.
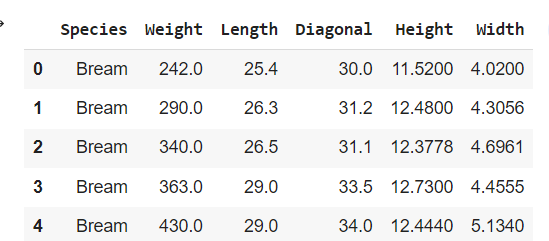
다음과 같은 구조가 data frame이다.
pandas에서 제공하는 unique api는 각 항목에 대한 고유한 값을 나타낼 수 있다.
여기서는 weight, Length, Diagonal, Height, width항목을 이용해서 species를 맞추는 작업을 할 것이다.
따라서 weight, Length, Diagonal, Height, width는 train_input으로 species는 target_input즉 정답지로 분류할 것이다.
fish_input = fish[['Weight', 'Length',
'Diagonal', 'Height', 'Width']].to_numpy()
# 데이터 프레임에서 species를 맞추기 위한 목적으로 두고 다른 5개의 카테고리를 input data로 설정해준다.
print(fish_input[:5])
fish_target = fish['Species'].to_numpy()
# 맞춰야하는 target으로 species설정
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42)
# 훈련세트와 test set으로 나눈다.fish_input을 species를 맞추기 위한 항목들로 설정해주고 fish_target은 species로 설정해준다. 그 후 scikit-learn의 train_test_split함수를 이용해서 train_input, train_target, test_input, test_target으로 나눠준다.
2. 데이터 표준화
앞선 포스팅에서는 데이터들의 평균을 구하고 표준편차를 구한 뒤 (값 - 평균) / 표준편차의 방법으로 데이터를 표준화했지만 scikit-learn에서는 StandardScaler라는 표준화 api를 제공한다. 이 api를 사용하여 데이터를 표준화해준다.
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
# 표준화 전처리3. KNNClassifier를 이용하여 학습 시키기
표준화 된 데이터를 KneighborsClassifier모델에 넣어 학습시켜준다. scikit-learn라이브러리의 학습 api는 대부분 fit으로 동일하다.
kn = KNeighborsClassifier(n_neighbors=3)
kn.fit(train_scaled, train_target)
print(kn.score(train_scaled, train_target))
print(kn.score(test_scaled, test_target))
print(kn.classes_) # 아까 에측하려던 species의 고유한 값들
print(kn.predict(test_scaled[:5])) # 표준화 된 test_input을 모델로 예측해본다.고려할 neighbor의 수는 3으로 설정해주었다.
그 후 모델의 score를 한 번 확인해보겠다.
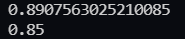
train_input에 대해서는 89%의 정확도 test_input에 대해서는 85%의 정확도를 보여주고 있다.
우리는 다중분류를 사용했기 때문에 모델은 우리의 데이터를 앞서 데이터의 unique값의 수 즉 7개로 나눈다. 그리고 이 값은 kn.classes_라는 변수에 들어있다. 확인해보면 다음과 같다.

표준화된 test_input 처음 5개를 확인해보면 다음과 같이 나온다.

4. 집합 별 가능성 확인
아무리 정교한 분류 모델이라도 무조건 이 집합이다 100%다라고 나오는 경우는 드물다 따라서 이 모델이 판단한 test_input들의 각 집합 별로의 가능성을 확인해볼 것이다.
proba = kn.predict_proba(test_scaled[:5]) # 클래스 별 확률
print(np.round(proba, decimals=4)) # 소수점 네 번째 자리까지 표기, 다섯 번째 자리에서 반올림.
distances, indexes = kn.kneighbors(test_scaled[3:4])
print(train_target[indexes])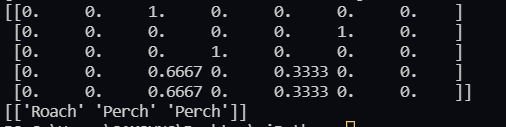
결과는 다음과 같이 나온다. 한꺼번에 보면
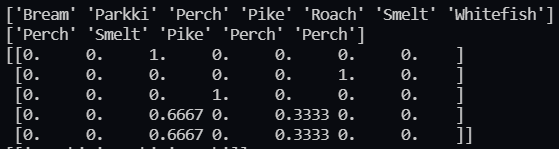
맨 위는 분류 집합들의 범주이다. 두 번째는 test_input의 처음 5개의 분류 값이다. 3번째는 test_input의 처음 5개에 대한 각 집합별로 가능성이다. 보면 perch가 3번째인데 첫번째 데이터 셋에서 3번째에 1이 있는 것을 확인할 수 있다. 이는 perch일 확률이 100%라는 것이다. 하지만 4번째 데이터 셋을 확인해보면 세 번째의 값이 0.6667 5번째의 값이 0.3333이 나온 것을 확인할 수 있다. 이는 이 생선이 perch일 확률 0.6667 Roach일 확률 0.3333이라는 뜻이다. 앞서 우리가 KNN모델을 학습시킬 때 고려할 neighbor의 수로 3을 줬었다. 이 때 4번째 데이터에 가장 가까운 이웃 3개 중 2개는 Perch, 1개는 Roach라는 뜻이다.
'파이썬 > ai' 카테고리의 다른 글
| [ai, python] 인천광역시 집값 예측 프로젝트- 데이터 전처리 2 (0) | 2022.05.18 |
|---|---|
| [ai, Python] 인천시 집 값 예측 프로그램-1(데이터 수집 및 전처리1) (2) | 2022.05.17 |
| [Ai, Python] Linear Regression- 4 (2) | 2022.04.11 |
| [Ai, python]KNN - Linear Regression3 (0) | 2022.04.11 |
| [ai, python]KNN에서의 overFitting UnderFitting (2) | 2022.04.11 |
댓글